How I Won Jeopardy With Data Science
When I got The Call letting me know I had been selected to appear on Jeopardy late July of this year, I went through the range of feelings every contestant gets: excitement, nervousness, anticipation. And like all other contestants, I started to put together a plan to prep for the show and give myself the best chance of winning. Most Jeopardy preparation strategies involve three main areas: buzzer training, board navigation, and good old fashioned studying. The first two were pretty straightforward. Secrets of the Buzzer by Fritz Holznagel outlined a buzzer strategy and practice method that answered all of my questions on how to get good at the buzzer. And even though I knew I would be nowhere near James Holzhauer’s ability, my sports betting background also gave me a willingness to bet big on Daily Doubles, so copying his strategy of trying to build a good dollar amount and go hunting for doubles seemed as good a template to follow as any. I knew the third area- the actual studying of potential questions- would be the trickiest for me to generate any kind of competitive advantage.
Jeopardy rewards frequent viewers of the show with commonly reused clues about answers that come up often. These clues, often referred to as “Pavlov clues,” are usually identified with a keyword phrase where the answer is almost always the same. Examples include “Iowa painter” ,which is almost always Grant Wood, or “Polish composer/pianist” and Frederic Chopin. These Pavlov clues are arguably the most valuable pieces of information to memorize when preparing: if you only focus on the Pavlov parts of the clues, you don’t need to memorize everything else about the subjects. Sounds great in theory, right? The problem: I knew I had not watched nearly as much Jeopardy as most of the other contestants I would be up against. I also knew my overall trivia knowledge base was good enough to pass the auditions and get on the show, but I wasn’t sure it was at a good enough level to win. What’s more, the return from the COVID break in filming meant the show was on an accelerated filming schedule. Most players get around four weeks to prepare for their show; I would have only two weeks. In short: I had to find a way to consume as much Jeopardy as possible in a very short amount of time to get my knowledge base up to speed.
The Plan
The natural place to start was the J! Archive, an online record of every Jeopardy game dating back to 1984. The format of the site makes it pretty easy to replay old games as a study method, but I knew if I just played through as many games on there as I could, it wouldn’t be enough to extract the Pavlov clues from scratch. I also knew some knowledge areas of mine were weaker than others, so I needed a way to prioritize what to study. Using some readily available open-source Python packages, I scraped all of the roughly 400,000 questions from J-Archive onto my computer, extracted the questions into a local database, and began partitioning the questions by category. I knew it would be impractical to try and memorize every answer in every category, so I settled for narrowing it down to only the most common occurring answers in each category. As an example, here are the most common answers for question on religion/the Bible, an area I knew I was weak in, based on how often the answer appears in the questions:
One approach for learning the Pavlov clues for these answers would be to read each of the questions one by one and memorize what words come up most often. However, this would probably take too much time: reading and rereading 51 questions on Solomon alone might take hours; memorizing an entire category might take days. Instead, I opted to use some natural language processing algorithms to see if I could automatically extract the most commonly occurring phrases for each answer and put them in study-friendly visualizations that I could quickly cycle through in place of reading questions one at a time.
The basic approach for extracting the relevant parts of a given clue is as follows: take the raw text of the question, remove punctuation marks and “stop words” (low-information words like “a”, “an”, “the”, etc.) from the text, and collapse words with similar conjugations (“tradition”, “traditions”, “traditionally”,”traditional”) into their common stem (all of those words become “tradition”). As an example, here is how one of the original questions appeared where the answer is Solomon:
“The book of Ecclesiastes is traditionally ascribed to this wise king”
And here is how it looks after the process described above:
“book ecclesiast tradit ascrib wise king”
The real value of stripping the clues down to their core words is they can be easily combined in a word cloud to see which words come up most often, which is exactly what the Pavlov clues should reflect. I liked putting the words in a word cloud not only to study as much material as possible, but it was also close to a visual representation of the actual clues I would see on the Jeopardy board, potentially making recall a little easier under the bright lights and pressure of the actual game. Here is what the word cloud for Solomon looks like when all of the clues are combined:
This provides a pretty clear picture: Solomon’s Pavlov clue is “wise king”, with a lesser emphasis on whenever King David is mentioned. The net effect is I was able to read the most important parts of all clues on Solomon in roughly 10 seconds instead of the hours it would have taken otherwise.
I repeated this process for every category and generated a series of word cloud flash cards for each topic, which became the basis for my studying. Overall, there were about 1500 cards I studied across every topic I could reliably parse.
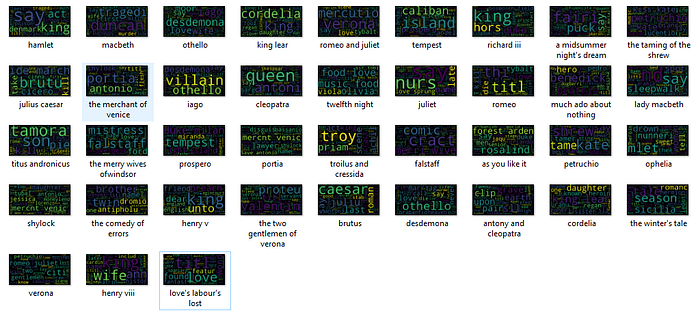
Some of the extracted Pavlov clues matched what longtime viewers of the show said they would be; Chopin’s card, for example, is pretty much a one-to-one match:
Others were a little more surprising. Here is what Dwight Eisenhower’s card looks like:
Most of the study guides on presidents usually emphasize Eisenhower being born in Texas, but all of his Jeopardy clues reference his living in Kansas way more often, which seemed to be a Jeopardy-specific clue. I was slowly becoming more confident I was extracting useful patterns from the clues that might not be obvious, potentially giving me an advantage in my round.
The Results

So, how did it actually play out on the show? There were three high-leverage spots where the cards definitely helped me pick up answers I wouldn’t have gotten otherwise. In the first round, here was the $1000 clue in the “Literary Characters” category:
And here is the card for “A Confederacy of Dunces”, the answer to the question:
Quirks of the stemming algorithm aside, the card is almost a perfect match to the actual question itself. The other two spots came in an even more critical moment. After finding both Daily Doubles in the second round and doubling up off the first one, I had a sizable lead, but had it chipped away over the round and briefly lost it with only a couple questions left:

Here is the first question that came up after I lost the lead, in the “Explorers” category for $1600:
And here was the card for Timbuktu, the correct answer:
Mali is the most common clue associated with Timbuktu, but Gordon Laing (slightly truncated by the stemming process) also comes up often enough to be highly visible in the word cloud. It was the linkage I needed to pull the trigger and give the correct answer.
5 questions later, here was the $2000 “Explorers” question when I was clinging to a $1000 lead:
And here was the card for Antarctica, which helped me get the answer:
The left side of the card showed me that the Ross Ice Shelf (and the Ross Sea) comes up for Antarctica way more often than I would have guessed otherwise. “Ice shelf” ended up being one of my strongest quick associations for Antarctica going into the round, and it ended up being just enough information for me to get the answer right. The total value of these questions ($3600 from the last two, plus $2000 from an eventually doubled-up $1000 clue) ended up being $5600, which was just more than my final lead of $5300 going into Final Jeopardy. We all ended up getting the Final Jeopardy question right, so if I didn’t have that lead at the end, I wouldn’t have been able to walk a way with a win.
Everyone comes to Jeopardy with different backgrounds, abilities, and skill sets, all of which play a role in how they do on the show. I didn’t think I would be the best pure trivia person in the studio that day, but I knew I was pretty good at finding ways to extract value from data, and I was determined to turn that into a competitive advantage. I’ve done a lot of interesting data science applications and projects in the last couple years, but I’m not sure I’ll ever be able to top using that knowledge to win the show I’ve wanted to be on for as long as I can remember.

Colin Davy is a consulting data scientist in San Francisco. You can get a hold of him at colin.e.davy@gmail.com .